forest_kfold command
See also
random forest classifiers
forest_train command
forest_classify command
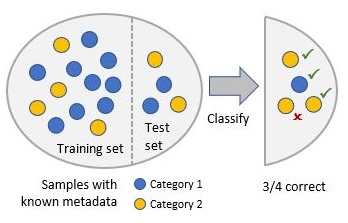 Performs
k-fold cross-validation of
random forest classifiers on a
feature table with known categories.
Performs
k-fold cross-validation of
random forest classifiers on a
feature table with known categories.
For K iterations, a classifier is trained and
its accuracy measured by splitting the data into a test set and training
set.
The number of iterations k is given by the
-tries option. Default 6.
By default, the test set is a random subset size 1/K
of the observations, and the training set is the remaining (K - 1)/K
observations. This can be changed by the -testpct option which specifies the
size of the test set as a percentage. For example, using -tries 5 -testpct
10 will perform five iterations where the test set is 1/10th of the
observations.
The -tabbedout option specifies a
k-fold validation tabbed output file.
Example
usearch -forest_kfold feature_table.txt -tabbedout
results.txt



